(3) SELECT 基础查询
1 查询资料前的基本概念
1.1 表格、纪录与栏位
表格是资料库储存资料的基本元件,它是由一些栏位组合而成的,储存在表格中的每一笔纪录就拥有这些栏位的资料。以储存城市资料的表格「city」来说,设计这个表格的人希望一个城市资料需要包含编号、名称、国家代码、区域和人口数量,所以他为「city」表格设计了这些「栏位(column)」:
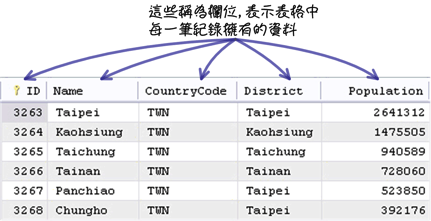
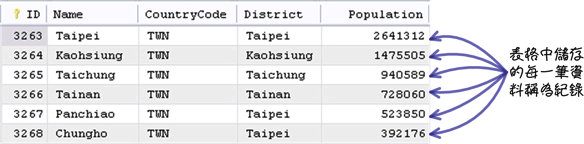
储存在表格中的每一笔资料称为「列(row)」或「纪录(record)」:
在设计表格的时候,通常会指定一个栏位为「主索引键(primary key)」:
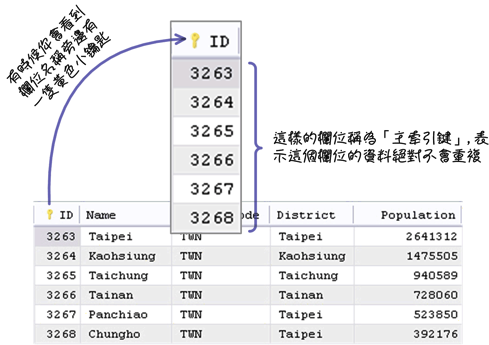
注:主索引键会在「第八章、表格与索引」中详细的讨论。
1.2 认识资料型态
资料库中可以储存各种不同的资料,SQL提供许多不同的「资料型态」让你应付这些不同的需求。在开始查询资料之前,你要先认识最常见、也是最基本的资料型态。第一种是数值,为了更精准的保存数值资料,SQL提供整数与小数两种数值型态:

你可以依照自己的需求,使用储存的数值资料执行数学运算:
常用的资料型态还有「字串」与「日期」:
在SQL叙述中使用字串资料的时候,字串资料的前后要使用单引号或双引号:

使用日期资料的时候,MySQL资料库预设的日期格式是「年-月-日」。与字串资料一样,前后也要使用单引号或双引号:

注:字串与日期资料型态会在「第七章、储存引擎与资料型态、栏位资料型态」中详细的讨论。
另外一种在资料库中比较特殊的资料型态是「NULL」,它不像数值、字串或日期资料型态是一个明确的资料,「NULL」是用来表示「不确定」、「未知」或「没有」的资料:

2 查询叙述
在执行资料库的操作中,查询算是最常见也是最复杂的工作,所以一个查询叙述所使用到的子句也最多,下列是查询叙述的基本语法:

这一章会讨论「SELECT」、「FROM」、「WHERE」、「ORDER BY」和「LIMIT」五个子句组合起来的查询叙述。其它的子句会在下一章继续讨论。
在你使用「SELECT」搭配各种子句来查询资料时,要特别注意子句使用的顺序:

就算你每一个子句的写法都没有出错,如果顺序不对了:

2.1 指定使用中的资料库
一个资料库伺服器可以建立许多需要的资料库,所以在你执行任何资料库的操作前,通常要先指定使用的资料库。下列是指定资料库的指令:

如果你使用「MySQL Workbench」这类的工具软体,画面上看起来会像这样:

2.2 只有SELECT
一个SQL查询叙述一定要以「SELECT」子句开始,再搭配其它的子句完成查询资料的工作。你可以单独使用「SELECT」子句,只不过这样的用法跟资料库一点关系都没有,它只不过把你输入的内容显示出来而已:

例如下列的查询叙述,只是简单的显示字串和计算结果,并不会查询资料库中的资料:
- SELECT 'My name is Simon Johnson', 35 * 12
2.3 指定栏位与表格
一般所谓的查询叙述,通常是查询资料库中的资料,所以「SELECT」子句会搭配「FROM」子句来使用,而「SELECT」后面可以指定「*」表示要查询指定表格的所有栏位:

如果目前使用中的资料库为「world」,下列的叙述可以查询「world」资料库中,「city」表格的所有资料:
- SELECT * FROM city
一个资料库伺服器可以建立许多需要的资料库,所以在你执行任何资料库的操作前,都要使用「USE」叙述指定一个使用中的资料库。不过你也可以在SQL叙述中使用下列的语法来指定资料库:

如果目前使用中的资料库是「world」,你不用先使用「USE cmdev」叙述切换使用中的资料库,可以使用下列的语法查询「cmdev」资料库中的「emp」表格:
- SELECT * FROM cmdev.emp
2.4 指定需要的栏位
有时候你并不需要查询一个表格中所有的栏位,所以你可以在「SELECT」子句后面自己指定需要的栏位:

如果你在「SELECT」后面使用「*」的话:
你可以依照自己的需要决定要查询哪些栏位和顺序:

2.5 数学运算
除了查询表格中的栏位外,你可以加入任何需要的运算,这里先讨论一般常见的数学运算。下列是很常用来执行数学运算的运算子:
| 优先顺序 | 运算子 | 说明 | 范例 | 运算结果 |
|---|---|---|---|---|
| 1 | % | 余数 | 7 % 3 | 1 |
| 1 | MOD | 余数 | 7 MOD 3 | 1 |
| 1 | * | 乘 | 7 * 3 | 21 |
| 1 | / | 除 | 7 / 3 | 2.333 |
| 1 | DIV | 除(整数) | 7 DIV 3 | 2 |
| 2 | + | 加 | 7 + 3 | 10 |
| 2 | - | 减 | 7 – 3 | 4 |
注:优先顺序的数字从1开始,1表示优先权比较高,2比较低,以此类推。就跟一般数学运算的先乘除后加减一样:在一个运算式中,优先权高的先算完,再换低优先权继续算;同样优先权的就由左到右计算。你也可以在运算式中使用左右括号,括号中的运算会先执行。
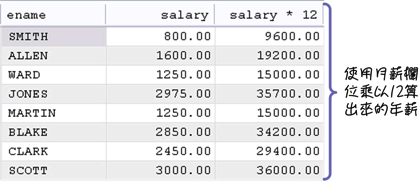
以「cmdev」资料库中的员工表格(emp)来说,想要计算员工的年薪,就可以使用这些运算子来完成你的查询工作:

2.6 别名
你可以另外为「SELECT」后面查询的资料取一个自己想要的名称,这个作法称为「别名(alias
name)」:

取栏位别名会让执行查询后的结果,使用你自己取的名称为栏位名称:

注:帮一般栏位取一个栏位别名是比较没有必要的,如果是运算式的话,通常就要帮它取一个栏位别名来取代原来一大串的运算式。
在取栏位别名的时候要特别注意下列的状况:

另外如果你「坚持」要使用SQL语法中的保留字来当作栏位别名的话:

如果违反上列两个规定,执行叙述以后会发生错误。
3 条件查询
使用「SELECT」和「FROM」执行的查询叙述,是把你在「FROM」子句指定表格里所有的纪录传回来。资料库最大的好处就是可以随时依照需要查询部份纪录资料,你可以搭配「WHERE」子句执行查询条件的设定:

3.1 比较运算子
要使用「WHERE」执行查询条件的设定,你会使用下列基础的比较运算子:
|优先顺序 |运算子| 说明|
|1| =| 等于|
|1| `| 等于| |1| !=| 不等于| |1| ``| 大于| |1| >=`| 大于等于|
注:``运算子在后面「NULL值的判断」会讨论。
使用这些基础的比较运算子就可以完成一些简单的条件设定:

设定日期资料型态的条件也是很常见的:

3.2 逻辑运算子
查询条件的设定,有时候会像前面讨论的单一条件一样,并不会太复杂;不过也很常遇到在一个查询的需求中,需要设定一个以上的条件,那你就会用到下列的运算子:
| 优先顺序 | 运算子 | 说明 |
|---|---|---|
| 1 | NOT | 非 |
| 2 | && | 而且 |
| 2 | AND | 而且 |
| 3 | | | | 或 |
| 3 | OR | 或 |
| 3 | XOR | 互斥 |
「NOT」运算子比较特殊一些,在一般的需求中,比较不会用到它。以下列的需求来说:

如果想要查询国家代码是「TWN」,而且人口数量小于十万的城市,就必须设定两个条件,而两个条件之间,依照「而且」的需求,使用「AND」来结合两个条件:

如果想要查询国家代码是「TWN」或是「USA」的城市,在两个条件之间依照「或」的需求,使用「OR」来结合两个条件:

在逻辑运算子的介绍中,它们也同样有「优先顺序」的。如果你想要查询在欧洲(Europe)或非洲(Aftica)国家,而且人口数要小于一万。使用下列的查询条件所得到的资料,跟你想要的却不一样:

如果有多个查询条件的设定,全部都是「AND」或全部都是「OR」的话,就没有这类问题;如果查询条件中,有「AND」和「OR」同时出现的话,就要依照你的需要,视情况加上左右刮号来控制条件的设定:

3.3 其它条件运算子
一般的条件和逻辑运算子,已经可以应付大部份的查询条件需求。下列还有一些可以用在特殊用途或是提供替代写法的条件设定:
- BETWEEN … AND …:范围比较
- IN (…):成员比较
- IS:是…
- IS NOT:不是…
- LIKE:像…
「BETWEEN … AND …」用来执行一个指定范围条件的设定:

如果要查询人口数量在八万到九万之间的城市资料,可以有下列两种条件的写法,它们执行以后的结果是完全一样的:

使用「BETWEEN … AND …」的条件设定会包含指定的资料,所以下列两个查询条件所得到的结果就不一样了:

「BETWEEN … AND …」使用在日期资料时,也可以完成某一个日期范围的判断:

「IN (…)」使用在一组成员资料的比对条件设定:

下列两个查询叙述,都可以得到国家代码是「TWN、USA、JPN、ITA和KOR」的城市资料,可是使用「IN (…)」来设定条件的话,看起来会简洁很多:

3.4 NULL值的判断
在国家表格中,有一个储存平均寿命的栏位「LifeExpectancy」,不过资料库中的资料并没有很完整,所以有一些国家是没有这个资料的,所以会使用「NULL」值来表示:

如果想要查询没有平均寿命资料的国家,也就是平均寿命的栏位值是「NULL」,你可能会使用下列的叙述:
- SELECT Name, LifeExpectancy
- FROM country
- WHERE LifeExpectancy = NULL
上列的叙述执行以后,并没有传回任何纪录,这表示并没有资料符合你设定的查询条件。
所以「NULL」值的判断,不可以使用判断一般资料的条件设定:

注:``在判断一般资料的时候,跟「=」完全一样;不过它用在判断「NULL」资料的时候,效果跟「IS」一样。
如果换成要查询「有」平均寿命资料的国家,也就是平均寿命的栏位值不是「NULL」:

3.5 字串样式
在使用字串资料的条件判断时,会有一种很常见、也比较特殊的需求,像是「想要查询名称以w字元开始的城市」,如果你使用下列的查询叙述:
- SELECT Name FROM city WHERE Name = 'w'
这样的查询条件,当然不是「名称以w字元开始的城市」,而是名称只有一个「w」字元的城市。所以这类的查询就会使用下列这个特殊的条件设定:

上列语法中,在「LIKE」后面的「样版」字串中,会使用到下列两种「样版字元」:
- %:0到多个任何字元
- _ :一个任何字元
所以要查询「名称以w字元开始的城市」的话:

参考上列的作法,就可以延伸出其它的查询条件设定了:

上列的查询条件中,「w%」表示第一个字元是「w」就符合条件;「%w」表示最后一个字元是「w」就符合条件;最后一个「%w%」表示不论在什么位置有「w」字元,都符合条件。
另外一种样版字元「_」表示一个任何字元:

把这些样版中的底线换到后面的话:

你也可以搭配两种样版字元完成条件的设定:

甚至像查询「名称是三十(包含)个字元以上的城市」:

注:其实完成上列的查询条件的需求是不用这么麻烦的,在后面的章节会讨论比较简单的方式。
4 排序
在你执行任何一个查询以后,MySQL传回的资料是依照「自然」的顺序排列的。所谓的自然顺序,通常是资料新增到表格中的顺序,可是在资料库运作一段时间后,陆续会有各种不同的操作,所以这个「自然」顺序对你来说,通常是没什么意义的。
一般的查询通常会有资料排序上的需求,所以你会使用「ORDER BY」子句:

如果你希望在查询城市资料的时候,资料库会依照国家代码帮你排序的话:

你也可以指定资料排列的顺序为由大到小:

「ORDER BY」子句后面可以依照需求指定多个排序的资料:

「ORDER BY」子句后面指定多个排序资料的时候,都可以依照需求,各自指定资料排列的方式:

「ORDER BY」子句指定的资料可以是栏位名称、编号、运算式或是栏位别名:

虽然比较不会有下列这样的需求,不过你还是可以这样作:

注:资料排列的顺序在「第六章、字元集与资料库」与「第七章、储存引擎与资料型态」中进一步详细的讨论。
5 限制查询
5.1 指定回传纪录数量
在你执行一个查询叙述后,资料库会将你查询的资料传回来给你;如果你使用「WHERE」子句设定查询条件的话,资料库就只会传回符合条件的资料;除了上列的状况外,你也可以另外使用「LIMIT」子句指定回传纪录的数量:

如果你在「LIMIT」子句后面指定一个数字:

「LIMIT」子句后面也可以指定两个数字:

在查询叙述中,使用「ORDER BY」子句搭配「LIMIT」子句,就可以完成下列查询「排名」的工作:

注:如果出现类似「… LIMIT 1000000, 10」这样的查询叙述,虽然你只会得到十笔资料,资料库总共会查询一百万零一十笔资料,只不过资料库会帮你跳过前一百万笔;类似这样的需求,还是要使用「WHERE」子句先挑出想要的资料会比较好一些。
5.2 排除重复纪录
在一个查询叙述执行以后,资料库不会帮你检查回传的资料是否重复(回传的两笔纪录资料完全一样),在「SELECT」子句后面可以让你设定「回传的资料是否重复」:

没有使用「ALL」或「DISTINCT」的效果,跟你自己加上「ALL」的查询效果是一样的,资料库会依照你的查询传回所有的资料:

使用「DISTINCT」的话,资料库会特别执行回传纪录是否重复的检查:
