Android中XML解析-PULL解析
前面写了两篇XML解析的Dom和SAX方式,Dom比较符合思维方式,SAX事件驱动注重效率,除了这两种方式以外也可以使用Android内置的Pull解析器解析XML文件。 Pull解析器的运行方式与 SAX 解析器相似,也是事件触发的。Pull解析方式让应用程序完全控制文档该怎么样被解析,比如开始和结束元素事件,使用parser.next()可以进入下一个元素并触发相应事件。通过Parser.getEventType()方法来取得事件的代码值,解析是在开始时就完成了大部分处理。事件将作为数值代码被发送,因此可以使用一个switch对感兴趣的事件进行处理,只过PULL方式读xml回调方法返回的是数字。
Pull创建XML
创建XML先实例化一个序列化对象,之后的通过Tag进行操作:
public void createXML() {
// 初始化一个序列化对象
XmlSerializer serializer = Xml.newSerializer();
File path = new File(getFilesDir(), "BookTest.xml");
try {
FileOutputStream foStream = new FileOutputStream(path);
serializer.setOutput(foStream, "utf-8");
//设置文档<?xml version='1.0' encoding='utf-8' standalone='yes'?>
serializer.startDocument("utf-8", true);
//设置根节点
serializer.startTag(null, "Books");
for (int i = 1; i < 4; i++) {
//设置子节点
serializer.startTag(null, "Book");
serializer.attribute(null, "name", "书籍" + i);
serializer.startTag(null, "Title");
serializer.text("内容" + i);
serializer.endTag(null, "Title");
serializer.endTag(null, "Book");
}
serializer.endTag(null, "Books");
serializer.endDocument();
} catch (FileNotFoundException e) {
// TODO Auto-generated catch block
e.printStackTrace();
} catch (IllegalArgumentException e) {
// TODO Auto-generated catch block
e.printStackTrace();
} catch (IllegalStateException e) {
// TODO Auto-generated catch block
e.printStackTrace();
} catch (IOException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
}
生成的XML的结果:
<?xml version='1.0' encoding='utf-8' standalone='yes'?>
<Books>
<Book name="书籍1" >
<Title>
内容1
</Title>
</Book>
<Book name="书籍2" >
<Title>
内容2
</Title>
</Book>
<Book name="书籍3" >
<Title>
内容3
</Title>
</Book>
</Books>
Pull读取XML
首先看一张效果图:
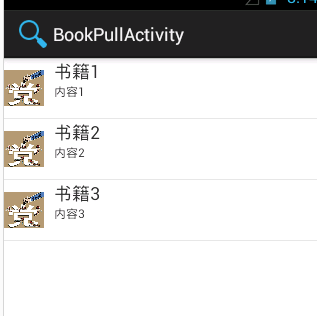
展示内容调用getListBooksByPull方法:
public List<Book> getListBooksByPull() {
list = new ArrayList<Book>();
File path = new File(getFilesDir(), "BookTest.xml");
try {
FileInputStream inputStream = new FileInputStream(path);
// 获得pull解析器对象
XmlPullParser parser = Xml.newPullParser();
// 指定解析的文件和编码格式
parser.setInput(inputStream, "utf-8");
int eventType = parser.getEventType(); // 获得事件类型
Book book = null;
while (eventType != XmlPullParser.END_DOCUMENT) {
String tagNameString = parser.getName();
switch (eventType) {
case XmlPullParser.START_TAG:
if ("Book".equals(tagNameString)) {//Book标签
book = new Book();
book.setName(parser.getAttributeValue(null, "name"));
} else if ("Title".equals(tagNameString)) {//Title标签
book.setTitle(parser.nextText());
}
break;
case XmlPullParser.END_TAG:
if ("Book".equals(tagNameString)) {
list.add(book);
}
break;
default:
break;
}
eventType = parser.next();//重新赋值,不然会死循环
}
} catch (FileNotFoundException e) {
// TODO Auto-generated catch block
e.printStackTrace();
} catch (XmlPullParserException e) {
// TODO Auto-generated catch block
e.printStackTrace();
} catch (IOException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
return list;
}
相对于Dom和SAX来说,Pull比较简单易读,不过简单的总结一下常用的几个方法:读取到xml的声明返回 START_DOCUMENT; 读取到xml的结束返回 END_DOCUMENT ; 读取到xml的开始标签返回 START_TAG ,读取到xml的结束标签返回 END_TAG 读取到xml的文本返回 TEXT .
Activity加载时候调用:
ListView listView = (ListView) findViewById(R.id.list_pull);
ArrayList<HashMap<String, String>> arrayList = new ArrayList<HashMap<String, String>>();
list = getListBooksByPull();
for (Book book : list) {
HashMap<String, String> map = new HashMap<String, String>();
map.put("itemTitle", book.getName());
map.put("itemText", book.getTitle());
arrayList.add(map);
}
SimpleAdapter simpleAdapter = new SimpleAdapter(this, arrayList,
R.layout.book, new String[] { "itemTitle", "itemText" },
new int[] { R.id.itemTitle, R.id.itemText });
listView.setAdapter(simpleAdapter);
简单回顾一下三种解析方式,Dom解析xml是先把xml文档都读到内存中,然后再用DOM API来访问树形结构,并获取数据。这个写起来很简单,但是很消耗内存。要是数据过大,手机配置不行可能会死机。SAX解析是对文档进行顺序扫描,当扫描到文档(document)开始与结束、元素(element)开始与结束、文档(document)结束等地方时通知事件处理函数,由事件处理函数做相应动作,然后继续同样的扫描,直至文档结束。Pull解析器和SAX解析器很相似,但SAX解析器的工作方式是自动将事件推入注册的事件处理器进行处理,因此你不能控制事件的处理主动结束;而Pull解析器的工作方式为允许你的应用程序代码主动从解析器中获取事件,正因为是主动获取事件,因此可以在满足了需要的条件后不再获取事件,结束解析。Pull的写法确实很轻巧也很容易上手,个人比较喜欢Pull。


")





